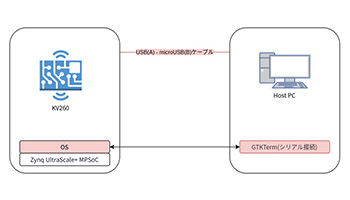
Kria Starter Kitで、Vitis AIを動かす
AIモデルのハイパーパラメータ調整
公開日:2023年7月31日
カスタムモデルを使用してみる では、AIモデル作成時のハイパーパラメータを精度を考慮せずに決めていました。
本記事ではAI推論の精度を確認して、より良いAIモデルになるように、ハイパーパラメータの調整を行います。
ハイパーパラメータとは
AIモデルの各層での重みやバイアスは、トレーニングデータにより自動で学習が行われますが、学習前に手動設定しなければならないパラメータが存在します。
そのパラメータをハイパーパラメータと呼びます。
精度確認、ハイパーパラメータ調整
カスタムモデルを使用してみる で使用しているハイパーパラメータは以下です。
| 設定名 | 値 | 意味 |
|---|---|---|
| Optimizer | adam | 最適化手法、他にもSGD(Stochastic Gradient Descent), RMSProp等が指定可能 |
| learning_rate | 0.001 | 学習率、adamのデフォルト値を使用 |
| 全結合層(Dense) | 128 | 全結合層 |
| Dropout | 0.2 | ノードをランダムに無視する層、過学習を防ぐ効果がある |
| バッチサイズ | 128 | 1回の学習で使用するトレーニングデータ数 |
| epoch数 | 30 | 全トレーニングデータで学習する回数 |
精度確認で数値の推移を見るため、epoch数は150に変更して確認を進めます。
カスタムモデルを使用してみるのコードでは、学習実行関数のfitの戻り値を無視していましたが、戻り値にはepoch毎のトレーニングデータとテストデータのloss(推論と正解のズレの指標)、accuracy(正答率)が含まれていますので、精度確認にはそれを使用します。
また、ハイパーパラメータの検証にはテストデータとは異なる検証用データが必要なので、訓練データから検証データを分離、fit関数のvalidation_dataに検証データを設定します。
コード例は以下です。
...
# load dataset
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
# validation data
# train : 50000
# validation : 10000
x_train, x_valid = np.split(x_train, [50000])
y_train, y_valid = np.split(y_train, [50000])
# normalization
x_train = x_train/255.0
x_valid = x_valid/255.0
x_test = x_test/255.0
...
h = mnist_model.fit(x_train, y_train, batch_size=128, epochs=150, validation_data=(x_valid, y_valid))
h.historyに以下の結果が入っています。
| 値 | 内容 |
|---|---|
| loss | トレーニングデータ損失 |
| accuracy | トレーニングデータの正答率 |
| val_loss | テストデータの損失 |
| val_accuracy | テストデータの正答率 |
epoch毎に値が入っているのでこれらをグラフ化することで確認を行います。
本記事ではハイパーパラメータは学習率と全結合数の2つのみ検証し、どちらも一回値を変更した場合での比較にしています。
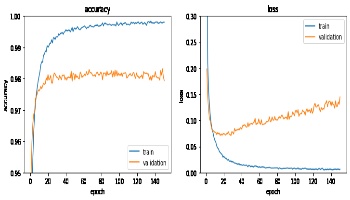
ハイパーパラメータ調整前の結果は以下グラフです。
ハイパーパラメーター調整前(クリックで拡大)
学習を繰り返すと検証データのlossが増加する傾向が見られます。
これは過学習(トレーニングデータでは精度が良いがテストデータで精度が上がらない現象)の傾向となります。
過学習の傾向を改善するため学習レートを下げてみます。
最適化でadamを指定していますが、デフォルトでは学習率が0.001なので0.0001に下げてみます。
学習率を下げることでlossの改善が期待できますが、学習に時間が掛かるデメリットもあります。
以下のようにコードを変更して、learning_rateを明示的に指定します。
mnist_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
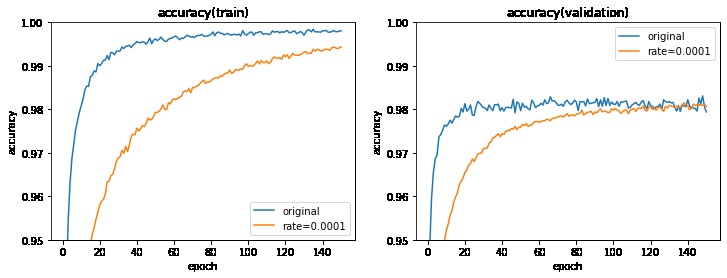
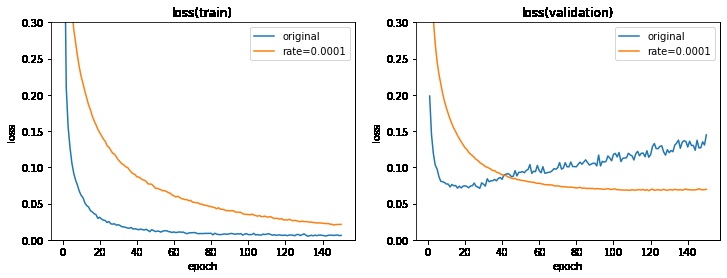
グラフ化して学習率の調整前後を比較してみます。
クリックで拡大
クリックで拡大
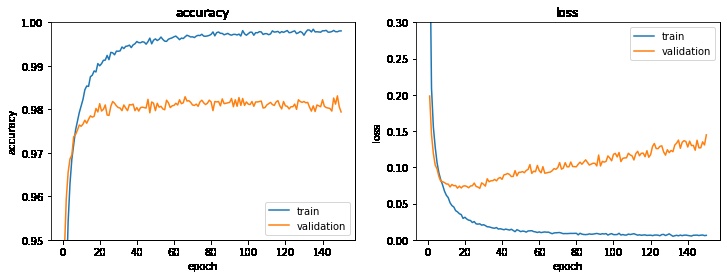
学習率を下げることで
- 検証データのlossの増加傾向がなくなる
- 検証データのaccuracyはほぼ変わらない
- トレーニングデータのaccuracy, lossはわずかに悪くなる
となることが分かりました。
着目すべきは検証データなので、トレーニングデータに関しては気にしなくても良さそうですが、
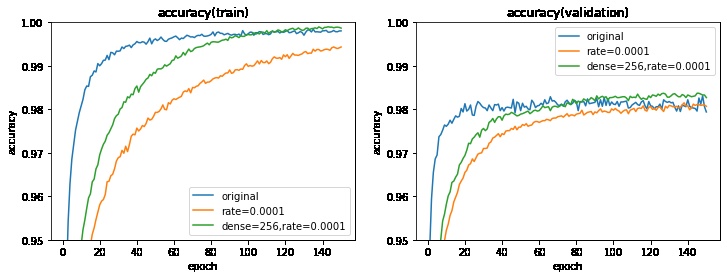
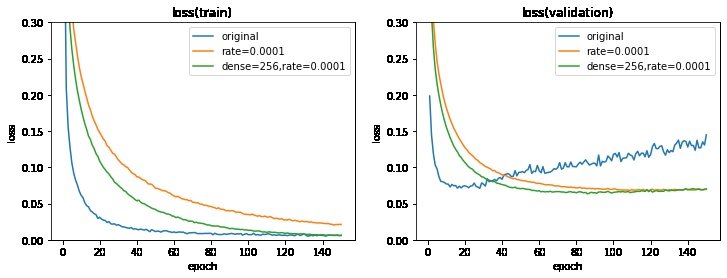
試しに全結合の数を128から256に増やしてみます。
全結合の数を増やすとAIモデルのサイズが増加し、計算量が増えるデメリットがあります。
クリックで拡大
クリックで拡大
全結合の数の変更により、検証データのlossのみ改善させることができました。また、グラフより早く学習が収束することが確認できます。
最後に、テストデータによる評価結果を以下にまとめます。
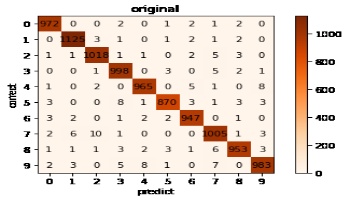
| 全結合数 | 学習率 | accuracy | loss |
|---|---|---|---|
| 128 | 0.001 | 0.981300 | 0.122410 |
| 128 | 0.0001 | 0.980500 | 0.064635 |
| 256 | 0.0001 | 0.983600 | 0.063561 |
最終的に過学習の傾向を改善し、学習の速度が早く、テストデータによる評価も一番良い結果となったので、
本記事では、以下のパラメータ調整を採用することにします。
- 全結合の数を増やす(128 -> 256)
- 学習レートを下げる(0.001 -> 0.0001)
- epoch数を150にする
確認用コード
本記事のグラフ作成、モデルの保存、テストデータの評価に使用したJupyter Notebookは、以下でダウンロードできます。
以下手順で確認が可能です。
- ホストPCでVitis-AI開発環境を起動し、conda activate vitis-ai-tensorflow2を入力
- 作業ディレクトリを作成して移動
- AI_Model_and_Log.ipynb を配置
- Jupyter Notebookを起動('jupyter notebook' コマンドを実行)
- ホストPCのブラウザで http://localhost:8888 にアクセス、tokenを入力
- AI_Model_and_Log.ipynb を選択して実行する
3種類のAIモデルの学習からグラフ作成までを行いますので、PCのスペックにも依存しますが、10分程度時間が掛かります。
まとめ
AIモデルの精度を確認して、ハイパーパラメータ調整による精度向上を行いました。
本記事では学習率と全結合数を、一つ候補を決めて改善確認を行いましたが、実際はいろいろな値を試して値を絞り込んでいく作業が発生します。
また、他のハイパーパラメータ(最適化関数を変更する、Dropoutの割合を変更する、AIモデルの設計見直し等)も調整の余地があります。
※文中に記載されている各種名称、会社名、商品名などは各社の商標もしくは登録商標です。