Kria Starter Kitで、Vitis AIを動かす
AI推論の精度比較
公開日:2023年7月31日
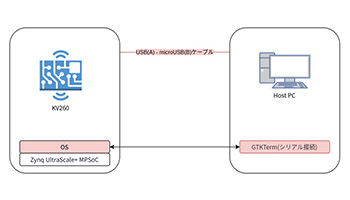
KV260でAI推論するまでに、学習済みモデルを量子化して、コンパイルすることになります。
この2回の変換作業でAI推論結果がどのように変わるかを確認してみます。
AIモデルの量子化
Xilinxデバイスで、AI推論を低レイテンシと高スループットで行うため、AIモデルのプルーニングと量子化技術が採用されています。
プルーニングは Vitis AI Optimizerが必要ですが、有償となりますので本記事では扱わず、量子化のみ扱います。
量子化とは、AIモデルのパラメータを小さいビット数で表現することにより、精度をそれほど落とさずにAIモデルの軽量化を行う手法です。
詳細は Vitis AI Quantizer Flow を参照してください。
可能な限り精度は保つように処理されますが、量子化前後で全く同一の結果にはならない点は注意が必要です。
AIモデルのKV260向けコンパイル
XilinxからVitis-AIコンパイラが提供されています。
コンパイラは、AIモデルを最適化されたDPU命令シーケンスにマップします。
コンパイル前後で同じ結果になるはずですが、実際にどうなるのか本記事で確認してみます。
コンパイルの詳細は Compiling the Model を参照してください。
比較用AIモデルの生成
AIモデルのパラメータ調整で確認用コードを実行済みである前提とします。
output_my_mnist_2 ディレクトリに存在しているのが、パラメータ調整済み学習済みモデルとなります。
以下のファイルが生成されているはずです。
| ファイル名 | 内容 |
|---|---|
| output_my_mnist_2/my_mnist_2.h5 | AIモデル |
| output_my_mnist_2/my_mnist_2_q.h5 | 量子化済みAIモデル |
KV260用のAIモデルが未作成のため、 カスタムモデルを使用してみる の手順でコンパイルします。
Vitis-AI開発環境を起動、 conda activate vitis-ai-tensorflow2を実行して以下コマンドで生成します。
ARCH=./arch.json
MY_MNIST_NANE=./output_my_mnist_2/my_mnist_2_q.h5
OUTDIR=output_my_mnist_xmodel
OUTNAME=my_mnist_2_q
vai_c_tensorflow2 \
--model ./${MY_MNIST_NANE} \
--arch ${ARCH} \
--output_dir ${OUTDIR} \
--net_name ${OUTNAME}
output_my_mnist_xmodel にKV260用のコンパイル済みAIモデルが出力されます。
| ファイル名 | 内容 |
|---|---|
| output_my_mnist_xmodel/my_mnist_2_q.xmodel | KV260用AIモデル |
正答率比較
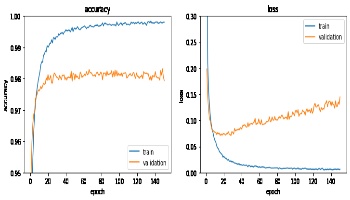
MNISTのテストデータ10000件に対する各AIモデルのaccuracy(正答率)を比較します。
| AIモデル | accuracy |
|---|---|
| host_pc_model.h5 | 98.36% |
| quantized_model.h5 | 98.32% |
| my_mnist_test.xmodel | 98.32% |
accuracyは量子化によりわずかに劣化しました。
コンパイルでは変化がありませんでした。
推論傾向比較
推論結果は量子化、コンパイルで異なる可能性があります。
オリジナルのAIモデルの推論傾向を確認し、量子化、コンパイル前後で、どの程度変化があるか確認してみます。
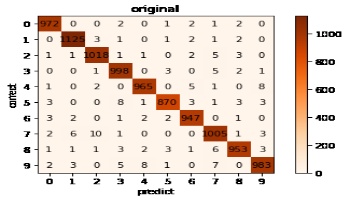
まずは、オリジナルのAIモデルの推論傾向を見てみます。
縦軸が正解で横軸がAI推論結果です。
間違いやすいのが9で、間違いにくいのが0という傾向が見られます。
また7を2と間違えるケースが一番多いようです。
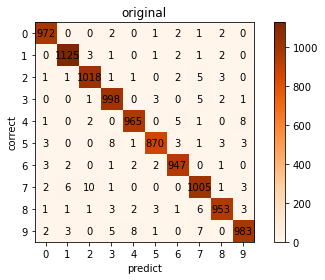
次に、オリジナルと量子化後の推論結果を比較してみます。
縦軸がオリジナルの推論結果、横軸が量子化後の推論結果になります。
正解かどうかは関係なく、推論結果がどの程度変わったのかの確認になります。
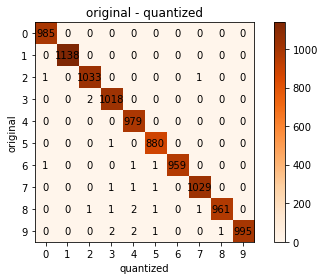
0,1,4は推論結果に変化なく、それ以外で変化がありました。
合計では23件変わることが分かりました。
最後に量子化後とコンパイル後の推論結果を比較してみます。
縦軸が量子化後の推論結果、横軸がコンパイル後の推論結果になります。
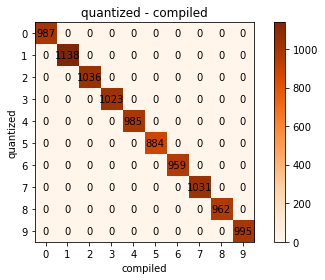
推論結果に変化はありませんでした。
確認により、量子化で推論結果が変わるケースがあることが分かりました。
accuracyの変化量以上に量子化前後に差があるため、オリジナルで正答するケースが量子化により誤答に変わる、またはその逆のケースが発生していると考えられます。
一方でコンパイルでは推論結果に変化はありませんでした。
まとめ
AIモデルの量子化、コンパイルによる精度、推論結果の比較を行いました。
MNISTの例のみですが、精度を落とさずにKV260で実行できていることを確認できました。
また量子化により、同一の推論結果にならないケースがあることも確認できたと思います。
※文中に記載されている各種名称、会社名、商品名などは各社の商標もしくは登録商標です。